import numpy as npimport matplotlib.pyplot as pltfrom mpl_toolkits.mplot3d import Axes3Dfrom IPython.display import Imageimport numpy as npimport matplotlib.pyplot as pltimport torch import torch.nn as nnimport torch.optim as optimfrom sklearn.datasets import make_circlesfrom sklearn.model_selection import train_test_splitfrom torch.utils.data import dataset ,dataloaderfrom termcolor import coloredimport matplotlib.pyplot as pltfrom mpl_toolkits.mplot3d import Axes3Dimport matplotlib.animation as animationfrom matplotlib import colors as mcolorsfrom IPython.display import HTMLdevice = ("cuda"if torch.cuda.is_available() else"cpu")SEED=1np.random.seed(SEED)torch.manual_seed(SEED)torch.backends.cudnn.deterministic =True
Optimization
In a nutshell, optimization is a minimization problem.But the question is what do we need to minimize in our Model Training.
In a Learning problem we have a Loss-Function or a Target function which is a mathematical way of measuring how wrong our predictions are.During the training process, we tweak and change the parameters (weights) of our model to try and minimize that loss function, and make our predictions as correct as possibl.So we need a way that tells us How do we change the parameters of our model, by how much, and when? and that way is by using Optimizers
Optimizers In simpler terms, optimizers shape and mold your model into its most accurate possible form by futzing with the weights. The loss function is the guide to the terrain, telling the optimizer when it’s moving in the right or wrong direction
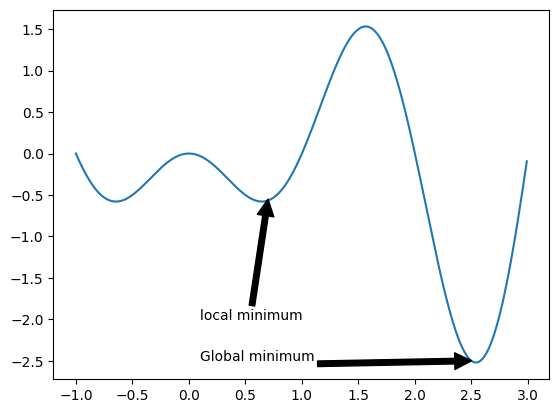
Let us understand this through an example: An objective function f(x) may have a local minimum x, where f(x) is smaller at x than at the neighboring points of x. If f(x) is the smallest value that can be obtained in the entire domain of x, f(x) is a global mininum. The following figure demonstrates examples of local and global minima for the function: \[ f(x) = x\cdot sin(-\pi x),−1.0 \leq x \leq 3.0.\]
Here from graph it is clear that using some optimization technique for a curve f(x) we need to find either one of the following: 1. An optimal Local minima 2. Global minima (Highly unlikely and difficult to find) When an optimal minima is found at that point the loss function gives the least value meaning the machine learning model is converged
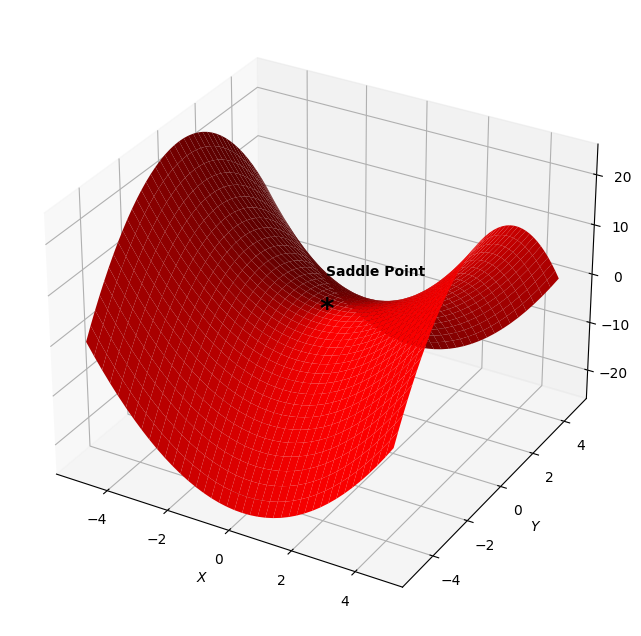
Saddle Point
Saddle point is problem for an optimizer because this point is neither local minima nor local maxima. If the figure shown below is cut through a constant x axis plane you will get a local maxima and if it’s cut through a constant y axis plane you will get a local minima
1. First Order Optimization
2. Second order Optimization
The approach we are going to take is named as Gradient Descent which is first order optimization technique, i.e we only use first derivative to calculate local minima
Gradient Descent
Any discussion about optimizers needs to begin with the most popular one, and it’s called Gradient Descent. This algorithm is used across all types of Machine Learning (and other math problems) to optimize. It’s fast, robust, and flexible.
Here’s how it works mthematically(back to Calculus I again!):
Consider a loss function f(x) that takes any multi-dimensional vector \[
x=[x1,x2,…,xd]^\top
\] as its input. The gradient of f(x) with respect to x is defined by the vector of partial derivatives: \[
\bigtriangledown f(x)=[\frac{\partial f(x)}{\partial x1},\frac{\partial f(x)}{\partial x2} , .... \frac{\partial f(x)}{\partial xd}]^\top.
\]
In simple terms,Gradients are partial derivatives, and are a measure of change.So in each element of \[ \frac{\partial f(x)}{\partial x1} \] of the gradient indicates the rate of change for f at the point x with respect to the input x1 only. To measure the rate of change of f in any direction that is represented by a unit vector u, in multivariate calculus, we define the directional derivative of f at x in the direction of u as \[\begin{align}
D_uf(x)=\lim h\to 0 \frac{f(x+hu)- f(x)}{h},
\end{align}\] which can be rewritten according to the chain rule as \[\begin{align}
D_uf(x)=\bigtriangledown f(x)\cdot u.
\end{align}\]
Since Duf(x) gives the rates of change of f at the point x in all possible directions, to minimize f, we are interested in finding the direction where f can be reduced fastest. Thus, we can minimize the directional derivative Duf(x) with respect to u. Since Duf(x)=∥∇f(x)∥⋅∥u∥⋅cos(θ)=∥∇f(x)∥⋅cos(θ), where θ is the angle between ∇f(x) and u, the minimum value of cos(θ) is -1 when θ=π. Therefore, Duf(x) is minimized when u is at the opposite direction of the gradient ∇f(x). Now we can iteratively reduce the value of f
with the following gradient descent update: \[\begin{align}
x=x− \eta \bigtriangledown f(x),
\end{align}\]
where the positive scalar η is called the learning rate or step size (discussed next).
If that is too much to sink in,let us try explaining it in simple english 1. Calculate what a small change in each individual weight would do to the loss function (i.e. which direction we should move in) 2. Adjust each individual weight based on its gradient (i.e. take a small step(determined by learning rate) in the determined direction) 3. Keep doing steps #1 and #2 until the loss function gets as low as possible
The Learning Rate
Changing our weights too fast by adding or subtracting too much (i.e. taking steps that are too large) can hinder our ability to minimize the loss function. We don’t want to make a jump so large that we skip over the optimal value for a given weight.
To make sure that this doesn’t happen, we use a variable called “the learning rate.” This thing is just a very small number, usually something like 0.001, that we multiply the gradients by to scale them. This ensures that any changes we make to our weights are pretty small. In math talk, taking steps that are too large can mean that the algorithm will never converge to an optimum.
At the same time, we don’t want to take steps that are too small, because then we might never end up with the right values for our weights. In math talk, steps that are too small might lead to our optimizer converging on a local minimum for the loss function, but not the absolute minimum.
For a simple summary, just remember that the learning rate ensures that we change our weights at the right pace, not making any changes that are too big or too small.
Gradient Descent Algorithm-Pseducode
for i inrange(num_epochs): grad = calculate_gradient(entire_data,param) param = param-learning_rate*grad
Stochastic Mini-Batch Gradient Descent
The problem with gradient descent is, it loads the entire data at once and then perform the gradient update so there is a memorey constraint. To solve this problem we use something called stochastic gradient descent.
In this technique we divide the entire data into mini batches and then calculate the gradient based on that batch and update the params according to that batch
for i inrange(num_epochs): np.random.shuffle(data)for each_batch in random_sample_batch(data=entire_training_data,batch_size=32): grad = calculate_gradient(entire_batch,param) param = param-learning_rate*grad
1.Shuffle the training data set to avoid pre-existing order of examples.
2.Partition the training data set into b mini-batches based on the batch size. If the training set size is not divisible by batch size, the remaining will be its own batch.
3.The batch size is something we can tune. It is usually chosen as power of 2 such as 32, 64, 128, 256, 512, etc. The reason behind it is because some hardware such as GPUs achieve better run time with common batch sizes such as power of 2
This technique is efficient and computationally tractable.
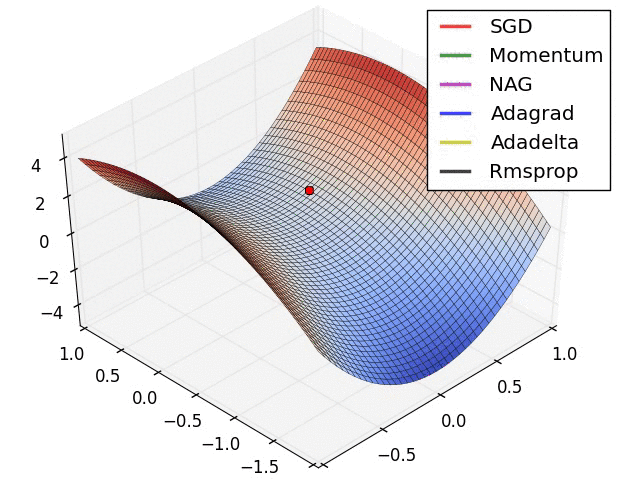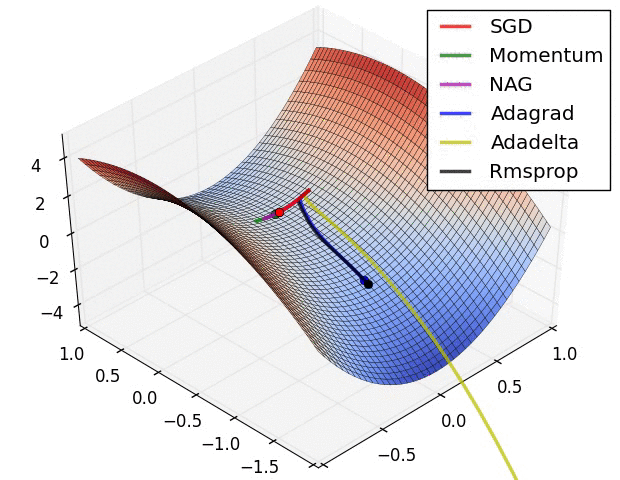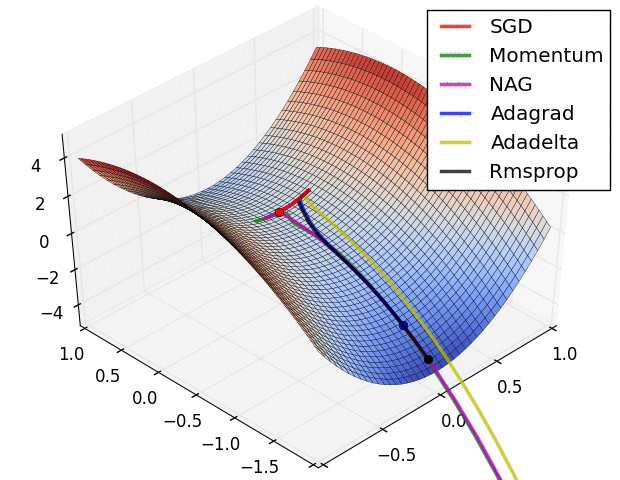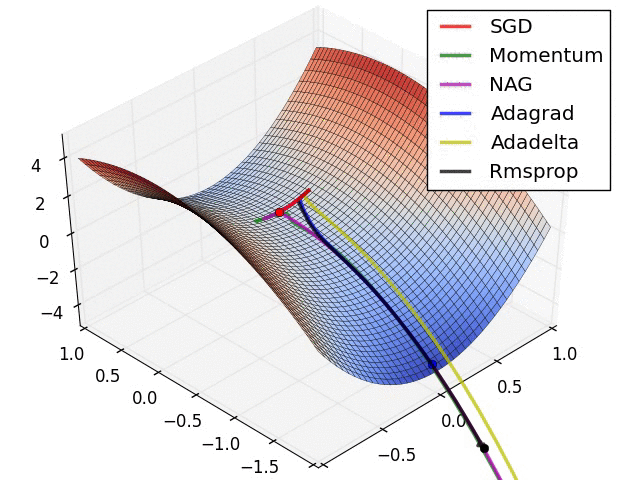
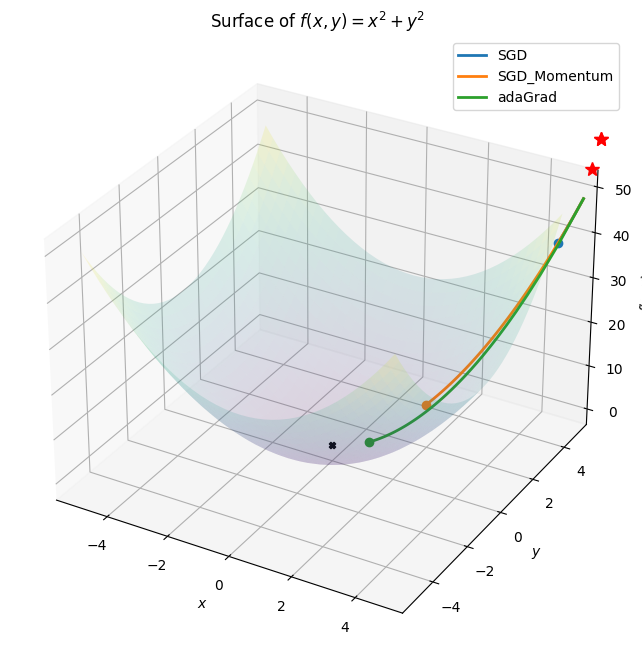
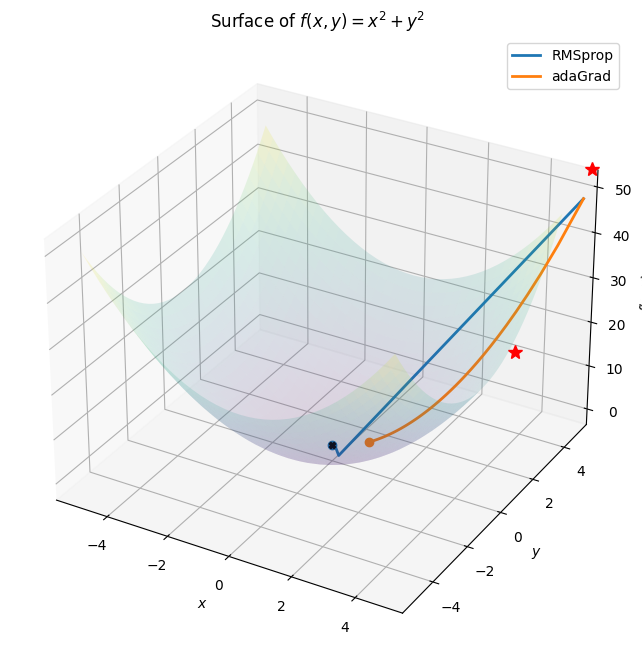
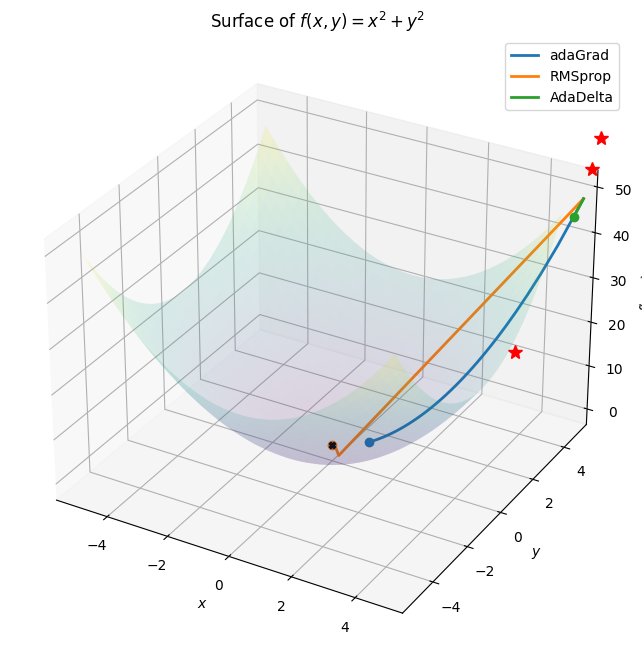
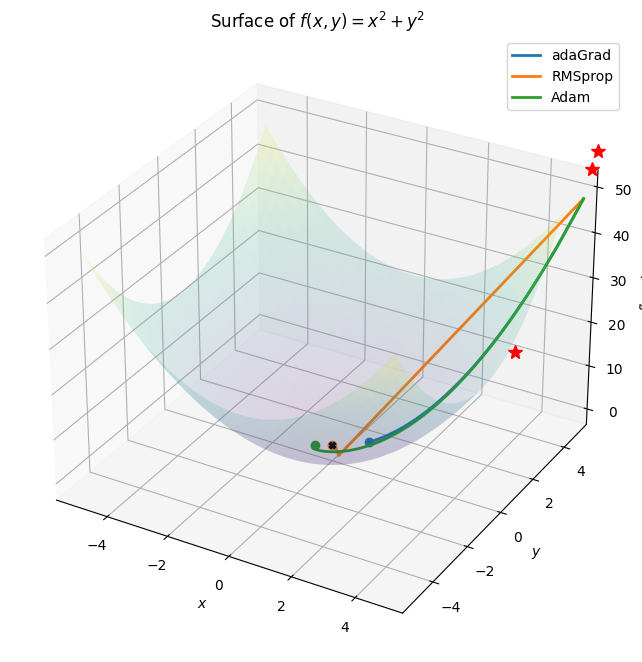
Other than SGD there are many more different optimization alogrithms which provide an efficient and faster convergence method by updating the weights and biases.Some of them are lsited below: 1. Nestrov Acclerated Gradient 2. Adagrad 3. Adadelta 4. RMSprop 5. Adam 6. AdaMax 7. Nadam 8. AMSGrad
Implementing Optimizers
Code
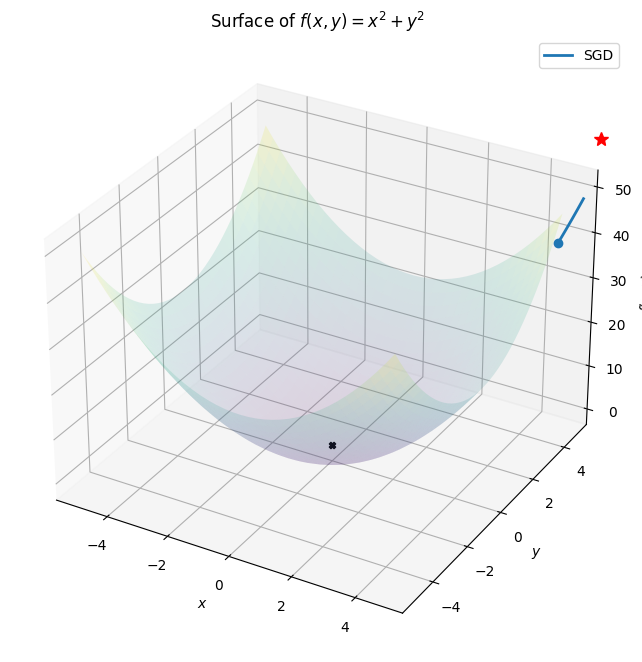
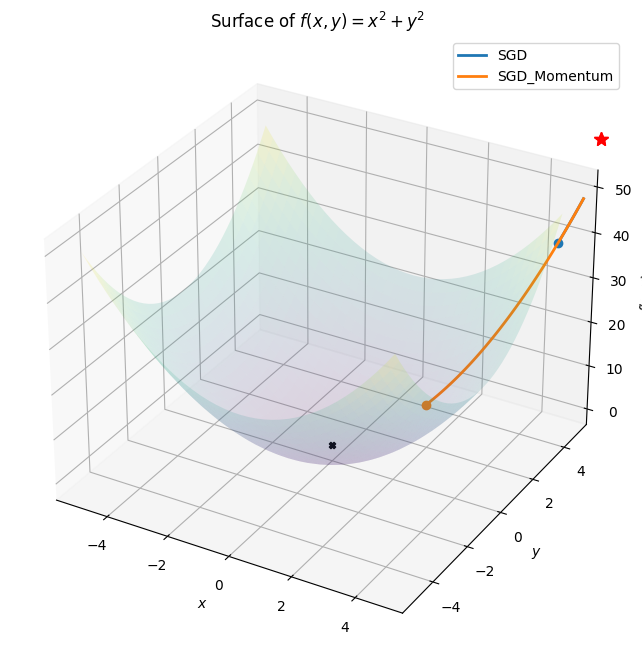
class Animation:def__init__(self,*vectorFunc):self.vectorFunc = vectorFuncself.fig = plt.figure(figsize=(12,8))self.ax = plt.axes(projection='3d')self.ax.set_title('Surface of $f(x,y) = x^{2} + y^{2}$')self.ax.set_xlabel('$x$')self.ax.set_ylabel('$y$')self.ax.set_zlabel('$f(x,y)$')self.colors = mcolors.TABLEAU_COLORS.values()def init(self): l = [] for i inrange(len(self.vectorFunc)): start =getattr(self,f"start_{i}")[0] start.set_data([],[]) start.set_3d_properties([]) path =getattr(self,f"path_{i}")[0] path.set_data([],[]) path.set_3d_properties([]) dot =getattr(self,f"dot_{i}")[0] dot.set_data([],[]) dot.set_3d_properties([]) l.extend([start,path,dot])self.ax.legend(l[1::3] ,[x.__name__for x inself.vectorFunc])returntuple(l)def animate(self,i): l = [] for j , vector inenumerate(self.vectors): start =getattr(self,f"start_{j}")[0] start.set_data([vector[0,0]],[vector[1,0]]) start.set_3d_properties([self.f(vector[0,0] , vector[1,0])]) path =getattr(self,f"path_{j}")[0] path.set_data(vector[0:i,0],vector[0:i,1]) path.set_3d_properties(self.f(vector[0:i , 0],vector[0:i,1])) dot =getattr(self,f"dot_{j}")[0] dot.set_data([vector[i,0]],[vector[i,1]]) dot.set_3d_properties([self.f(vector[i,0],vector[i,1])]) l.extend([start,path,dot])returntuple(l)def__call__(self,vector):self.f =lambda x,y :(x**2+ y**2 ) xlist = np.arange(-5, 5, 0.25) ylist = np.arange(-5, 5, 0.25) X,Y = np.meshgrid(xlist, ylist) # Create 2-D grid xlist,ylist values Z =self.f(X,Y) # Compute function values on the gridself.ax.plot_surface(X,Y,Z,cmap='viridis',alpha=0.15)self.ax.scatter([0],[0],[0],color="k" , marker="X")for i ,color inzip(range(len(self.vectorFunc)),self.colors):setattr(self,f"start_{i}", self.ax.plot([],[],[],'r*',markersize=10))setattr(self,f"path_{i}", self.ax.plot([],[],[],linewidth=2,color=color))setattr(self,f"dot_{i}", self.ax.plot([],[],'o',color=color))self.vectors = [func(vector.clone().detach().requires_grad_(True)) for func inself.vectorFunc] anim = animation.FuncAnimation(self.fig,self.animate,frames=len(self.vectors[0]),init_func=self.init)return anim.to_html5_video()
Nesterov momentum. Instead of evaluating gradient at the current position (red circle), we know that our momentum is about to carry us to the tip of the green arrow. With Nesterov momentum we therefore instead evaluate the gradient at this “looked-ahead” position.
AdaGrad
\[
cache = cache + (grad^2) \\
data = data - \frac {(lr * grad)}{( \sqrt {cache} + eps)}
\]
It is a adaptive learning method where we are constantly annealing the lr.
The eps is a extremely small value to smoothen the denominator.
Code
def adaGrad(vector): lr=0.5 cache = torch.zeros_like(vector) vectors = [vector.squeeze(0).tolist()] eps =1e-10# can be any small valuefor i inrange(EPOCHS): z = LOSS_FUNC(vector) z.backward()with torch.no_grad(): cache += (vector.grad **2) vector.data = vector.data - (lr * vector.grad / (torch.sqrt(cache) + eps)) vector.grad.zero_() vectors.append(vector.squeeze(0).tolist())return np.array(vectors)
It is all similar to RMSProp with an additional delta attribute which just eliminates the use of lr away from the update parameter.
The authors note that the units in this update (as well as in SGD, Momentum, or Adagrad) do not match, i.e. the update should have the same hypothetical units as the parameter. To realize this, they first define another exponentially decaying average, this time not of squared gradients but of squared parameter updates:
\[
m = beta1*m + (1-beta1)*dx \\
mt = \frac{m} {(1-beta1^t)} \\
v = beta2*v + (1-beta2)* dx^2 \\
vt = \frac{v} {(1-beta2^t)} \\
x = x - \frac{lr * mt}{np.sqrt(vt) + eps}
\]
Notice that the update looks exactly as RMSProp update, except the “smooth” version of the gradient m is used instead of the raw (and perhaps noisy) gradient vector dx. Recommended values in the paper are eps = 1e-8, beta1 = 0.9, beta2 = 0.999. In practice Adam is currently recommended as the default algorithm to use, and often works slightly better than RMSProp. However, it is often also worth trying SGD+Nesterov Momentum as an alternative. The full Adam update also includes a bias correction mechanism, which compensates for the fact that in the first few time steps the vectors m,v are both initialized and therefore biased at zero, before they fully “warm up”. With the bias correction mechanism, the update looks as follows:
Code
import mathdef Adam(vector): m = torch.zeros_like(vector) v = torch.zeros_like(vector) beta1 =0.9 beta2 =0.99 eps =1e-8 lr=0.2 vectors = [vector.squeeze(0).tolist()]for i inrange(1 , EPOCHS+1): z = LOSS_FUNC(vector) z.backward()with torch.no_grad(): m = m * beta1 + (1-beta1)*vector.grad v = v * beta2 + (1-beta2)*(vector.grad**2) denom = torch.sqrt(v)+eps bias_correction_m =1- beta1**i bias_correction_v =1- beta2**i step_size = lr * math.sqrt(bias_correction_v)/bias_correction_m vector.data = vector.data - step_size*m/denom vector.grad.zero_() vectors.append(vector.squeeze(0).tolist())return np.array(vectors)